
Seit Anfang der 2000er Jahre bietet Transvalor HPC-Lösungen an, mit denen ihre Kunden ihre Rechenleistung für noch genauere Ergebnisse voll ausschöpfen können.
Was ist paralleles Rechnen?
Die FORGE®-Software nutzt die Vorteile eines impliziten 3D-Lösers, der parallel läuft, d. h. die Berechnung wird auf mehrere CPU-Kerne aufgeteilt (oder verteilt), indem jedem Kern ein Teil des Netzes zugewiesen wird.
Durch die Aufteilung des Rechengebiets auf mehrere Prozessoren wird die Berechnungszeit erheblich verkürzt. Dies bedeutet auch, dass Netze mit einer großen Anzahl von Elementen verwendet werden können, um die Genauigkeit der Berechnungen zu verbessern.

Vorteile der Parallelisierung in FORGE®
- Volle Ausschöpfung der Rechenleistung für genauere Ergebnisse
- Verwalten Sie die Benutzerfreigaben nach Belieben: Mit einer 12-Benutzerfreigabe-Lizenz können Sie beispielsweise Simulationen mit 1x12 Kernen, 2x6 Kernen oder 3x4 Kernen durchführen. Es gibt keine Einschränkungen bei den möglichen Kombinationen.
- Erstklassige HPC-Leistungen
- Paralleles Rechnen ist für sämtliche Prozesse verfügbar
- Simulationen für bis zu 64 Kerne
- Parallele Effizienz bleibt über viele Kerne hinweg konstant
- Batch-Management und Job Scheduler
- Integrierter proprietärer Batch-Manager
- Unterstützt die meisten gängigen Job Scheduler unter Windows oder Linux
Was sind unsere Grundlagen?
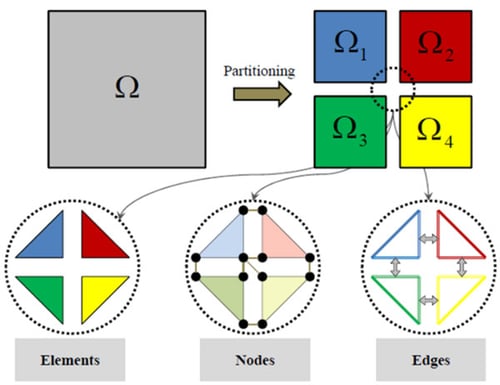
Die Parallelisierung von FORGE® basiert auf dem SPMD-Ansatz (Single Program Multiple Data), der darin besteht, dass dasselbe Programm auf mehreren Kernen ausgeführt wird, lediglich mit einem anderen Datensatz. Das Hauptprinzip zielt darauf ab, den Berechnungbreich in mehrere Teilbereiche (oder Unterteilbereiche) aufzuteilen und jedem Teilbereich einen Satz von Daten zuzuweisen, die zu verarbeiten sind.
Aufteilung eines Netzes auf mehrere Kerne (eine Farbe pro Kern)
Das Programm, das den Bereich aufteilt (der so genannte „Partitioner“), muss die Arbeitslast gleichmäßig auf Unterbereiche mit einer vergleichbaren Anzahl von Knoten und Elementen verteilen. Jeder Unterbereich wird dann einem CPU-Kern zugewiesen, auf dem eine lokale thermomechanische Finite-Elemente-Analyse durchgeführt wird. Die Gesamtlösung wird durch die Kommunikation zwischen den Kernen erzielt.
Vollständig parallele Software
Das Vernetzungsprogramm erzeugt Unterbereiche, in denen die Elemente zu einem einzigen Bereich gehören. Knoten werden an der Schnittstelle gemeinsam genutzt und auch die Kanten werden nach dem Paradigma der Knotenaufteilung gemeinsam genutzt [1].
Da FORGE® die Massivumformung von Metallen simuliert, ist in jedem Unterbereich ein Neuvernetzungsschritt erforderlich, sobald ein bestimmter Verformungsgrad erreicht ist. Die in der Software implementierten Algorithmen werden verwendet, um den Neuvernetzungsschritt parallel auf jedem Kern auszulösen. Sobald dies abgeschlossen ist, gleicht der „Partitioner“ die Arbeitslast zwischen den Kernen erneut aus und optimiert die Schnittstellengrößen zwischen den Teilbereichen. Durch die Minimierung der Anzahl der Knoten an der Schnittstelle wird die Größe der Steifigkeitsmatrix begrenzt und somit die Rechenzeit erheblich reduziert.
Schema der Bereichsverteilung im Kontext der Parallelberechnung
Starke Skalierbarkeit in FORGE®
Die parallele Berechnung hat ihre Grenzen, da mit der Anzahl der Verteilungen auch die Anzahl der Schnittstellen zunimmt. Die gemeinsamen Knoten zwischen zwei Teilbereichen müssen sich gleich verhalten und folglich ist an jeder Schnittstelle ein Kommunikationsschritt erforderlich, um die Kontinuität der Ergebnisse zwischen den Teilbereichen zu gewährleisten.
Die Simulationssoftware muss für parallele Berechnungen optimiert werden.
Interessanterweise kann die parallele Leistung mit zunehmender Anzahl von Kernen abnehmen. Falls die Größe des Teilbereichs im Vergleich zu den Schnittstellengrößen nicht groß genug ist, kann die Kommunikationszeit zwischen allen Schnittstellen größer sein als die für die Lösung des thermomechanischen Problems benötigte Rechenzeit. Daher ist die Verminderung der Schnittstellengröße zwischen den Teilbereichen von wesentlicher Bedeutung, um die Effizienz des parallelen Lösers zu steigern.
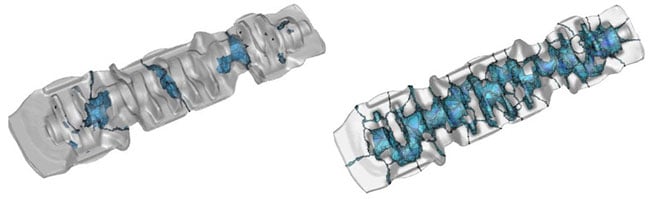 Inter-core interface node distribution
Inter-core interface node distribution
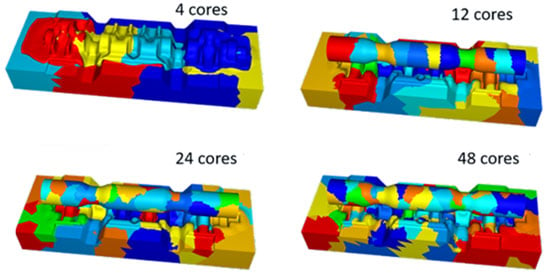
4 Kerne vs. 48 cores
Portable, Extensible Toolkit for Scientific Computation (PETSc) ist eine Reihe von Datenstrukturen und Routinen, die die Bausteine für die Implementierung umfangreicher Anwendungscodes auf parallelen (und seriellen) Computern bieten. PETSc umfasst eine wachsende Reihe paralleler linearer und nichtlinearer Gleichungslöser und Zeitintegratoren, die in Anwendungscodes verwendet werden können, welche in Fortran, C, C++, Python usw. geschrieben sind. Die PETSc-Bibliothek kann zur Lösung vieler wissenschaftlicher Funktionen wie Matrix-, Vektor- oder Matrix-Vektor-Multiplikationen verwendet werden. Sie verfügt auch über mehrere Auflösungsmethoden, einschließlich der Methode der konjugierten Residuen, die einen effizienten, parallelen Rechencode ermöglicht.
Anwendungsfall des Gesenkschmiedens von Kurbelwellen
Paralleles Rechnen ist für sämtliche FORGE®-Prozesse verfügbar. Darüber hinaus bleibt die Effizienz von FORGE® bei Berechnungen, die auf einer großen Anzahl von Kernen gestartet werden, nahezu konstant (Verhältnis Beschleunigung zu Anzahl der Kerne). Die Effizienzstudie wurde an einem Kurbelwellenschmiedefall mit verformbaren Gesenken durchgeführt (Abbildung 1).
Tabelle zeigt die Beschleunigung und die parallele Effizienz, die mit einer unterschiedlichen Anzahl von Kernen erreicht wird. Sp entspricht der Beschleunigung, die mit N Kernen im Vergleich zu N-1 erzielt wird.
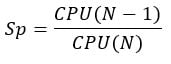 E entspricht der relativen parallelen Effizienz, die mit N Kernen im Vergleich zu N-1 erreicht wird.
E entspricht der relativen parallelen Effizienz, die mit N Kernen im Vergleich zu N-1 erreicht wird.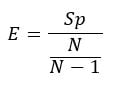
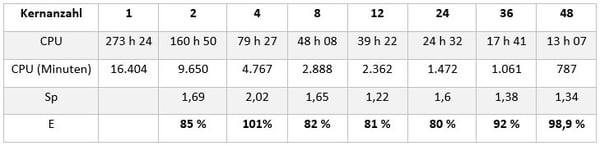
Die parallele relative Effizienz ist in rot eingezeichnet. Es ist zu erkennen, dass der FORGE®-Löser auch bei einer großen Anzahl von Kernen parallel effizient ist.
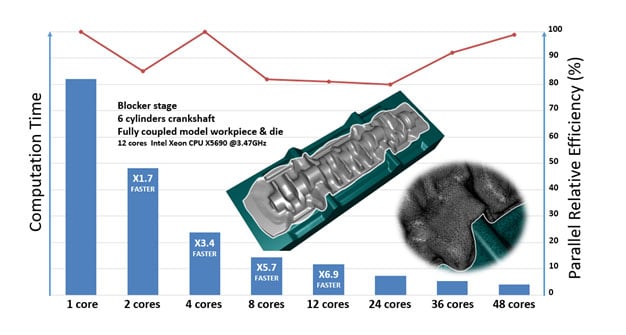
Abbildung 1: Beschleunigung des parallelen Rechnens dank starker Skalierbarkeit
