
Since the early 2000s, Transvalor has provided HPC solutions enabling its customers to fully exploit their computing power for even more accurate results.
What is Parallel Computing?
FORGE® software takes advantage of a 3D implicit solver that runs in parallel, meaning that computation is sub-divided (or spread) over several CPU cores by allocating a portion of the mesh onto each core.
This significantly reduces computation time by dividing the computation domain across several processors. This also means meshes with a substantial number of elements can be used to improve the precision of computations.

Advantages of parallelization in FORGE®
- Fully exploit computing power for more accurate results.
- Manage the pool of tokens as the user wishes: for example, with a 12-token license, it is possible to run 1x12-core, 2x6-core or 3x4-core simulations. There are no restrictions on the possible combinations.
- Best-in-class HPC performances.
- Parallel computing is available for every kind of process.
- Simulations for up to 64 cores.
- Parallel efficiency stays constant over many cores.
- Batch management and job scheduler.
- Embedded proprietary batch manager.
- Supports most popular job schedulers on Windows or Linux.
What are our fundamentals?
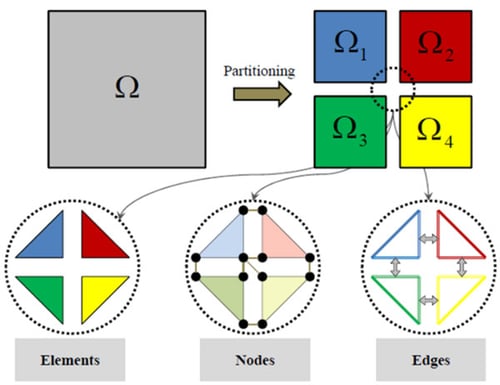
FORGE® parallelization is based on the SPMD (Single Program Multiple Data) approach that consists in executing the same program on several cores just with a different set of data. The main principle is aimed at dividing the calculation domain into several partitions (or sub-domains) and assigning a set of data to be processed on each partition.
Partitioning of a mesh on several cores (one color per core)
The program that splits the domain (the so-called ‘partitioner’) must balance the workload equally between sub-domains with a comparable number of nodes and elements. Each sub-domain is then assigned to a CPU core where a local thermo-mechanical finite element analysis is performed. The overall solution is obtained through communication between the cores.
Fully parallel software
The meshing program generates sub-domains in which elements belong to a single domain; nodes are shared at the interface, and edges are also shared following a nodal partitioning paradigm.
As FORGE® simulates bulk metal forming, a remeshing step is required on each sub-domain once a certain degree of deformation is reached. The algorithms implemented in the software are used to trigger the remeshing step in parallel on each core. Once this is completed, the ‘partitioner’ again balances the workload between the cores and optimizes the interface sizes between the sub-domains. Minimizing the number of nodes on the interface limits the size of the stiffness matrix and therefore considerably reduces computation time.
Scheme of domain partitioning in the parallel computation context
Strong scalability in FORGE®
Parallel computing may be limited because as the number of partitions increases, the number of interfaces increases as well. The nodes in common between two sub-domains must behave the same way and consequently a communication step is required at each interface to ensure the continuity of results between the sub-domains.
Simulation software needs to be optimized for parallel computing. Curiously, the parallel performance can decline as the number of cores increases. If the sub-domain sizes are not large enough compared to the interface sizes, then the communication time between all interfaces might be greater than the calculation time needed to solve the thermo-mechanical problem. Thus, minimizing the size of the interface between the subdomains is essential for increasing the efficiency of the parallel solver.
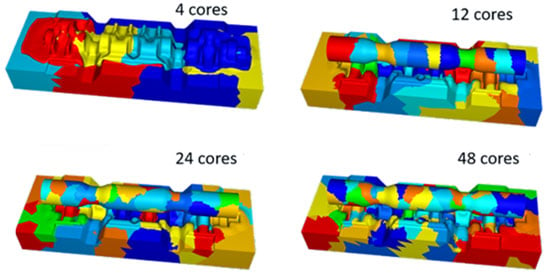
 Inter-core interface node distribution
Inter-core interface node distribution
4 cores vs. 48 cores
The Portable, Extensible Toolkit for Scientific Computation (PETSc) is a suite of data structures and routines that provide the building blocks for the implementation of large-scale application codes on parallel (and serial) computers. PETSc includes an expanding suite of parallel linear and nonlinear equation solvers and time integrators that may be used in application codes written in Fortran, C, C++, Python, etc. The PETSc library can be used to solve many scientific functions, such as matrix, vector, or matrix-vector multiplications. It also has multiple resolution methods, including the conjugate residual method, allowing for an efficient computational code in parallel.
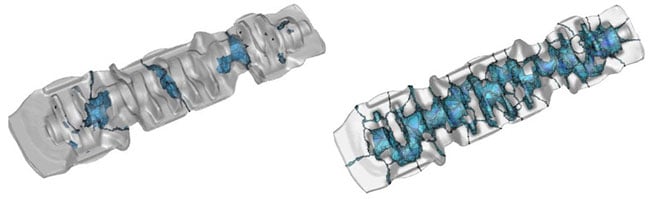
Application case of closed-die crankshaft forging
Parallel computing is available for all FORGE® processes. The efficiency study was performed on a crankshaft forging case with deformable dies.
The table below presents the speed-up and parallel efficiency attained using different numbers of cores. Sp corresponds to the speed-up obtained using N cores compared to N-1. 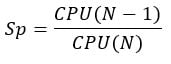 E corresponds to the parallel relative efficiency obtained using N cores compared to N-1.
E corresponds to the parallel relative efficiency obtained using N cores compared to N-1.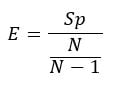
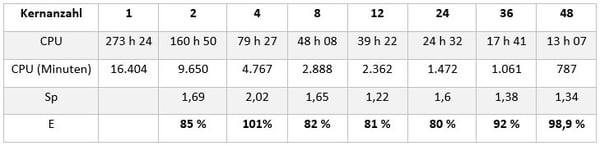
Moreover, FORGE® maintains nearly constant efficiency (ratio speed-up vs number of cores) for calculations launched on a large number of cores as shown in the figure below. Parallel relative efficiency is plotted in red. It can be seen that the FORGE® solver is efficient in parallel, even on a large number of cores.
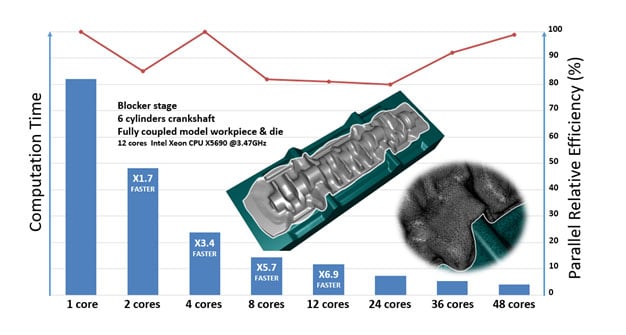
Speed-up of parallel computing thanks to strong scalability.
